0. 들어가며
https://aflplus.plus/docs/custom_mutators/
Custom Mutators | AFLplusplus
The AFLplusplus website
aflplus.plus
AFL++에는 custom mutator 라는 기능이 있다.
이를 이용해 grammer based input을 생성해내도록하거나 file input이 아닌 다른 방법으로 input을 전달할 수 있도록 고칠 수 있다고 하는데, 어떻게 하면 그렇게 사용할 수 있을지 사용해보았다.
AFL++는 기본적으로 파일을 입력으로 받는 프로그램에 대해서만 input을 전달하는 기능을 제공하기때문에, 이를 잘 이용하면 grammer based input을 udp와 같은 다양한 채널로 전송할 수 있을거라는 가정으로 분석해보게 되었다.


아래에서 진행하는 모든 실습코드는 아래 링크에서 확인해볼 수 있다.
https://github.com/junfuture1103/AFLToyDriver/tree/master/afl_custom_mutator_test
AFLToyDriver/afl_custom_mutator_test at master · junfuture1103/AFLToyDriver
AFL++_ToyDriver. Contribute to junfuture1103/AFLToyDriver development by creating an account on GitHub.
github.com
1. using specific file input + grammer based
1-1. Target Program 만들기
우선 기본적인 예제로 파일로 부터 인풋을 받는 Toy Program에 대해 사용을 해보았다.
첫번째 예제의 목표는 target program은 파일로 부터 인풋을 받지만, 특정한 파일에서만 인풋을 받고 (-i 옵션의 in 안의 파일들 X) grammer based의 인풋으로 전달하는 것이다. 이때 커버리지 측정과 out/ 디렉터리 안의 기록이 grammer based 로 저장되는지 확인한다.
아래와 같은 간단한 Toy program (target)을 만들어줬다.
단순히 프로그램 인자 argv[1]로 부터 파일 이름을 받고, 이 파일을 열어 그 안에 있는 값을 process_input이라는 함수에 넘겨 그 값에 따라 coverage를 넓힐 수 있는 Toy 예제이다.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define BUF_SIZE 1024
void process_input(const char *input) {
printf("process input : %s\n", input);
if (strncmp(input, "FUZZ", 3) == 0) {
printf("Detected FUZZ prefix\n");
if (strcmp(input, "FUZZ_AFL") == 0) {
printf("Exact match for FUZZ_AFL\n");
} else if (strcmp(input, "FUZZ_TEST") == 0) {
printf("Exact match for FUZZ_TEST\n");
} else {
printf("FUZZ prefix but not an exact match\n");
}
} else {
printf("No FUZZ prefix\n");
}
if (strstr(input, "CRASH") != NULL) {
printf("CRASH found in input, triggering error...\n");
abort(); // This will cause a crash for testing
}
}
int main(int argc, char *argv[]) {
printf("argc : %d argv[1] : %s\n", argc, argv[1]);
if (argc != 2) {
fprintf(stderr, "Usage: %s <input_file>\n", argv[0]);
return 1;
}
FILE *file = fopen(argv[1], "r");
if (file == NULL) {
perror("fopen");
return 1;
}
char buffer[BUF_SIZE];
if (fgets(buffer, BUF_SIZE, file) != NULL) {
process_input(buffer);
} else {
perror("fgets");
}
fclose(file);
return 0;
}
아래와 같이 타겟 컴파일을 해줬다.
afl-gcc-fast -o afl_file_input afl_file_input.c1-2. Custom Mutator 만들기
이후 Custom Mutator를 만들어준다.
아래의 링크를 참고해서 만들었으며, ./foo라는 파일에 값을 써주고
AFL++ 에서는 해당 파일의 내용을 읽어 값을 전달한다.
https://github.com/AFLplusplus/AFLplusplus/blob/stable/custom_mutators/examples/custom_send.c
AFLplusplus/custom_mutators/examples/custom_send.c at stable · AFLplusplus/AFLplusplus
The fuzzer afl++ is afl with community patches, qemu 5.1 upgrade, collision-free coverage, enhanced laf-intel & redqueen, AFLfast++ power schedules, MOpt mutators, unicorn_mode, and a lot more!...
github.com
//
// This is an example on how to use afl_custom_send
// It writes each mutated data set to /tmp/foo
// You can modify this to send to IPC, shared memory, etc.
// in pwd PATH : /home/jun20/jun/etc/AFLToyDriver/afl_custom_mutator_test
//
// cc -O3 -shared -fPIC -o custom_send.so -I /AFLplusplus/include afl_custom_mutator.c
// cd ../..
// afl-gcc-fast -o afl_file_input afl_file_input.c
// AFL_CUSTOM_MUTATOR_LIBRARY=/home/jun20/jun/etc/AFLToyDriver/afl_custom_mutator_test/custom_send.so \
// afl-fuzz -i in -o out -- ./afl_file_input ./foo
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include "afl-fuzz.h"
typedef struct my_mutator {
afl_state_t *afl;
} my_mutator_t;
my_mutator_t *afl_custom_init(afl_state_t *afl, unsigned int seed) {
my_mutator_t *data = calloc(1, sizeof(my_mutator_t));
if (!data) {
perror("afl_custom_init alloc");
return NULL;
}
data->afl = afl;
return data;
}
void afl_custom_fuzz_send(my_mutator_t *data, uint8_t *buf, size_t buf_size) {
int fd = open("./foo", O_CREAT | O_NOFOLLOW | O_TRUNC | O_RDWR, 0644);
if (fd >= 0) {
//printf("buf in custom mutator : %s\n", buf);
(void)write(fd, buf, buf_size);
close(fd);
}
return;
}
void afl_custom_deinit(my_mutator_t *data) {
free(data);
}
이때 AFL github 예시에서는 -f 옵션을 통해 파일을 지정해줬는데, 그렇게 하면 -f 문자열 자체를 프로그램의 argv로 전달해버려서 오류가 났다. 따라서 아래와 같은 커맨드로 실행을 하니 잘 되었다.
AFL_CUSTOM_MUTATOR_LIBRARY=/home/jun20/jun/etc/AFLToyDriver/afl_custom_mutator_test/custom_send.so AFL_DEBUG=1 \
afl-fuzz -i in -o out -- ./afl_file_input ./foo

1-3. custom mutator에 grammer based 설정 (afl_custom_fuzz_send 수정)
이후 custom mutator 코드에 아래와 같이 수정을 해주면, 항상 해당 grammer에 맞는 인풋만을 타겟 프로그램에 전달한다.
이때 방법이 두가지가 있는데,
a. afl_custom_fuzz_send를 수정하는 방법
b. afl_custom_post_process과 afl_custom_fuzz를 수정하는 방법
이 있다.
1-3 에서는 a만을 이용해서 진행해본다.
void afl_custom_fuzz_send(my_mutator_t *data, uint8_t *buf, size_t buf_size) {
// "FUZZ"의 길이는 4이므로, 새로운 버퍼의 크기를 계산
size_t new_buf_size = buf_size + 4;
// 새로운 버퍼를 동적으로 할당
uint8_t *new_buf = (uint8_t *)malloc(new_buf_size);
if (new_buf == NULL) {
// 메모리 할당에 실패한 경우 오류 처리
return;
}
// 새로운 버퍼의 앞부분을 "FUZZ"로 설정
new_buf[0] = 'F';
new_buf[1] = 'U';
new_buf[2] = 'Z';
new_buf[3] = 'Z';
// 원래 버퍼의 내용을 새로운 버퍼에 복사
memcpy(new_buf + 4, buf, buf_size);
int fd = open("./foo", O_CREAT | O_NOFOLLOW | O_TRUNC | O_RDWR, 0644);
if (fd >= 0) {
(void)write(fd, new_buf, new_buf_size);
close(fd);
}
// 동적으로 할당한 메모리를 해제
free(new_buf);
return;
}
정확히는 AFL++가 생성한 인풋에다가 Target Program에 전달하기 직전에 "FUZZ" 문자열을 붙여서 전달하는 것이기 때문에, AFL++ 입장에서는 전달한 인풋이 "FUZZ"가 붙어있는지 알지못한다.
무슨뜻이냐면,
아래와 같이 타겟 프로그램이 받는 문자열의 형태는
"FUZZ*"의 형태가되지만 Fuzzer 입장 즉, AFL++의 입장에서는 내가 생성한 인풋만을 기록해두게 된다.
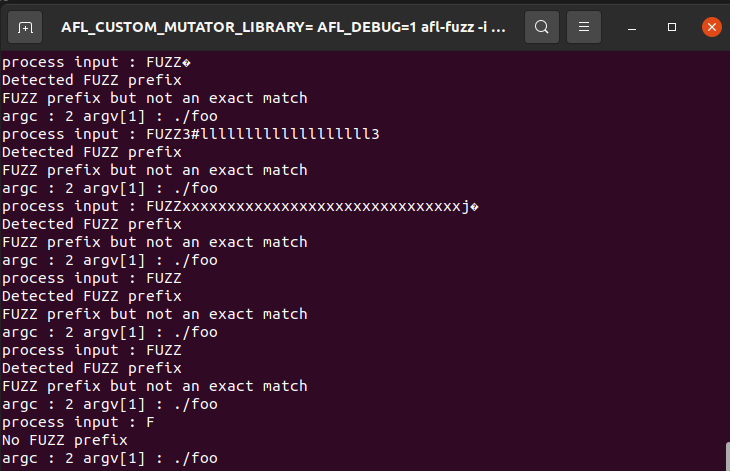
또한 해당 input이 coverage를 넓히거나 crash를 유발하는 등 기타 AFL++가 설정한 조건에 해당되는경우 퍼저가 생성한 인풋만을 저장하게된다.
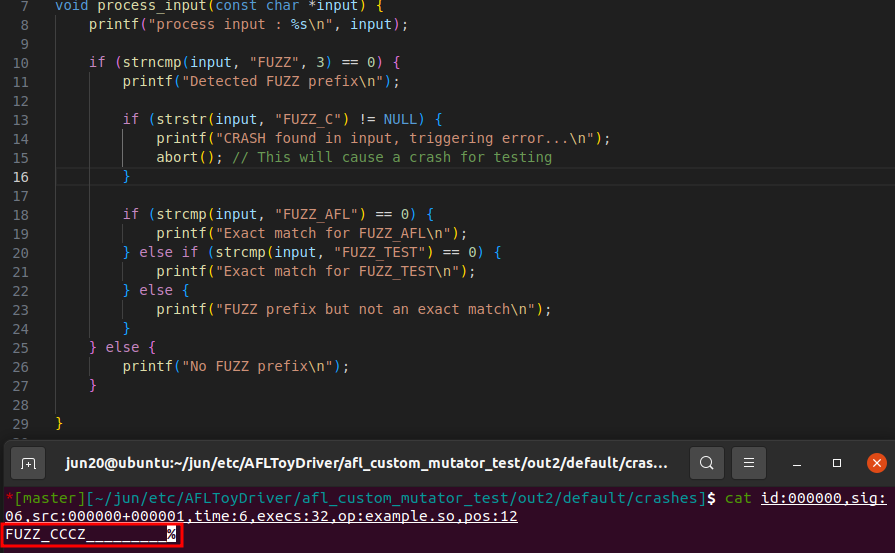
위의 방법대로 퍼징을 했을때 아래와 같이 crash를 저장하는 모습을 볼 수 있다.
이를 보면 이해가 잘 될 것이다.

위처럼 Fuzzer는 _C 인풋을 crash로 저장했다.
이때 Target Program은 FUZZ_C 인풋을 받아야 크래시를 유발하는데, 이런 현상이 발생한 이유는
Fuzzer 입장에서는 내가 뮤테이션 완료한 값 (_C) 이 Target program에 전달되기 직전에 FUZZ라는 문자열이 붙는다는 사실을 모르기 때문이다.
따라서 당연히 reproduce를 할때도 Fuzzer가 기록한 crash에다가 custom mutator에 적은 grammer를 덧붙여 전송해야될 것이다.
1-4. custom mutator에 grammer based 설정 (afl_custom_post_process & afl_custom_fuzz 수정)
사실 이 방법이 정석적이다.
Fuzzer가 생성한 인풋에다가 내가 정의한 규칙을 넣고 이 인풋을 기억하라고 전달할 수 있기 때문이다.
아래와 같은 코드를 이용하면
/*
New Custom Mutator for AFL++
Written by Khaled Yakdan <yakdan@code-intelligence.de>
Andrea Fioraldi <andreafioraldi@gmail.com>
Shengtuo Hu <h1994st@gmail.com>
Dominik Maier <mail@dmnk.co>
*/
// You need to use -I/path/to/AFLplusplus/include -I.
#include "afl-fuzz.h"
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#define DATA_SIZE (100)
static const char *commands[] = {
// "GET",
// "PUT",
// "DEL",
"AAA",
"BBB",
"CCC",
};
typedef struct my_mutator {
afl_state_t *afl;
// any additional data here!
size_t trim_size_current;
int trimmming_steps;
int cur_step;
u8 *mutated_out, *post_process_buf, *trim_buf;
} my_mutator_t;
/**
* Initialize this custom mutator
*
* @param[in] afl a pointer to the internal state object. Can be ignored for
* now.
* @param[in] seed A seed for this mutator - the same seed should always mutate
* in the same way.
* @return Pointer to the data object this custom mutator instance should use.
* There may be multiple instances of this mutator in one afl-fuzz run!
* Return NULL on error.
*/
my_mutator_t *afl_custom_init(afl_state_t *afl, unsigned int seed) {
srand(seed); // needed also by surgical_havoc_mutate()
my_mutator_t *data = calloc(1, sizeof(my_mutator_t));
if (!data) {
perror("afl_custom_init alloc");
return NULL;
}
if ((data->mutated_out = (u8 *)malloc(MAX_FILE)) == NULL) {
perror("afl_custom_init malloc");
return NULL;
}
if ((data->post_process_buf = (u8 *)malloc(MAX_FILE)) == NULL) {
perror("afl_custom_init malloc");
return NULL;
}
if ((data->trim_buf = (u8 *)malloc(MAX_FILE)) == NULL) {
perror("afl_custom_init malloc");
return NULL;
}
data->afl = afl;
return data;
}
/**
* Perform custom mutations on a given input
*
* (Optional for now. Required in the future)
*
* @param[in] data pointer returned in afl_custom_init for this fuzz case
* @param[in] buf Pointer to input data to be mutated
* @param[in] buf_size Size of input data
* @param[out] out_buf the buffer we will work on. we can reuse *buf. NULL on
* error.
* @param[in] add_buf Buffer containing the additional test case
* @param[in] add_buf_size Size of the additional test case
* @param[in] max_size Maximum size of the mutated output. The mutation must not
* produce data larger than max_size.
* @return Size of the mutated output.
*/
size_t afl_custom_fuzz(my_mutator_t *data, uint8_t *buf, size_t buf_size,
u8 **out_buf, uint8_t *add_buf,
size_t add_buf_size, // add_buf can be NULL
size_t max_size) {
// Make sure that the packet size does not exceed the maximum size expected by
// the fuzzer
size_t mutated_size = DATA_SIZE <= max_size ? DATA_SIZE : max_size;
memcpy(data->mutated_out, buf, buf_size);
// Randomly select a command string to add as a header to the packet
memcpy(data->mutated_out, commands[rand() % 3], 3);
if (mutated_size > max_size) { mutated_size = max_size; }
*out_buf = data->mutated_out;
return mutated_size;
}
/**
* A post-processing function to use right before AFL writes the test case to
* disk in order to execute the target.
*
* (Optional) If this functionality is not needed, simply don't define this
* function.
*
* @param[in] data pointer returned in afl_custom_init for this fuzz case
* @param[in] buf Buffer containing the test case to be executed
* @param[in] buf_size Size of the test case
* @param[out] out_buf Pointer to the buffer containing the test case after
* processing. External library should allocate memory for out_buf.
* The buf pointer may be reused (up to the given buf_size);
* @return Size of the output buffer after processing or the needed amount.
* A return of 0 indicates an error.
*/
size_t afl_custom_post_process(my_mutator_t *data, uint8_t *buf,
size_t buf_size, uint8_t **out_buf) {
if (buf_size + 5 > MAX_FILE) { buf_size = MAX_FILE - 5; }
memcpy(data->post_process_buf + 5, buf, buf_size);
// data->post_process_buf[0] = 'A';
// data->post_process_buf[1] = 'F';
// data->post_process_buf[2] = 'L';
// data->post_process_buf[3] = '+';
// data->post_process_buf[4] = '+';
data->post_process_buf[0] = 'F';
data->post_process_buf[1] = 'U';
data->post_process_buf[2] = 'Z';
data->post_process_buf[3] = 'Z';
data->post_process_buf[4] = '_';
*out_buf = data->post_process_buf;
return buf_size + 5;
}
/**
* This method is called at the start of each trimming operation and receives
* the initial buffer. It should return the amount of iteration steps possible
* on this input (e.g. if your input has n elements and you want to remove
* them one by one, return n, if you do a binary search, return log(n),
* and so on...).
*
* If your trimming algorithm doesn't allow you to determine the amount of
* (remaining) steps easily (esp. while running), then you can alternatively
* return 1 here and always return 0 in post_trim until you are finished and
* no steps remain. In that case, returning 1 in post_trim will end the
* trimming routine. The whole current index/max iterations stuff is only used
* to show progress.
*
* (Optional)
*
* @param data pointer returned in afl_custom_init for this fuzz case
* @param buf Buffer containing the test case
* @param buf_size Size of the test case
* @return The amount of possible iteration steps to trim the input.
* negative on error.
*/
int32_t afl_custom_init_trim(my_mutator_t *data, uint8_t *buf,
size_t buf_size) {
// We simply trim once
data->trimmming_steps = 1;
data->cur_step = 0;
memcpy(data->trim_buf, buf, buf_size);
data->trim_size_current = buf_size;
return data->trimmming_steps;
}
/**
* This method is called for each trimming operation. It doesn't have any
* arguments because we already have the initial buffer from init_trim and we
* can memorize the current state in *data. This can also save
* reparsing steps for each iteration. It should return the trimmed input
* buffer, where the returned data must not exceed the initial input data in
* length. Returning anything that is larger than the original data (passed
* to init_trim) will result in a fatal abort of AFLFuzz.
*
* (Optional)
*
* @param[in] data pointer returned in afl_custom_init for this fuzz case
* @param[out] out_buf Pointer to the buffer containing the trimmed test case.
* External library should allocate memory for out_buf.
* AFL++ will not release the memory after saving the test case.
* Keep a ref in *data.
* *out_buf = NULL is treated as error.
* @return Pointer to the size of the trimmed test case
*/
size_t afl_custom_trim(my_mutator_t *data, uint8_t **out_buf) {
*out_buf = data->trim_buf;
// Remove the last byte of the trimming input
return data->trim_size_current - 1;
}
/**
* This method is called after each trim operation to inform you if your
* trimming step was successful or not (in terms of coverage). If you receive
* a failure here, you should reset your input to the last known good state.
*
* (Optional)
*
* @param[in] data pointer returned in afl_custom_init for this fuzz case
* @param success Indicates if the last trim operation was successful.
* @return The next trim iteration index (from 0 to the maximum amount of
* steps returned in init_trim). negative ret on failure.
*/
int32_t afl_custom_post_trim(my_mutator_t *data, int success) {
if (success) {
++data->cur_step;
return data->cur_step;
}
return data->trimmming_steps;
}
/**
* Perform a single custom mutation on a given input.
* This mutation is stacked with the other muatations in havoc.
*
* (Optional)
*
* @param[in] data pointer returned in afl_custom_init for this fuzz case
* @param[in] buf Pointer to the input data to be mutated and the mutated
* output
* @param[in] buf_size Size of input data
* @param[out] out_buf The output buffer. buf can be reused, if the content
* fits. *out_buf = NULL is treated as error.
* @param[in] max_size Maximum size of the mutated output. The mutation must
* not produce data larger than max_size.
* @return Size of the mutated output.
*/
size_t afl_custom_havoc_mutation(my_mutator_t *data, u8 *buf, size_t buf_size,
u8 **out_buf, size_t max_size) {
*out_buf = buf; // in-place mutation
if (buf_size <= sizeof(size_t)) { return buf_size; }
size_t victim = rand() % (buf_size - sizeof(size_t));
(*out_buf)[victim] += rand() % 10;
return buf_size;
}
/**
* Return the probability (in percentage) that afl_custom_havoc_mutation
* is called in havoc. By default it is 6 %.
*
* (Optional)
*
* @param[in] data pointer returned in afl_custom_init for this fuzz case
* @return The probability (0-100).
*/
uint8_t afl_custom_havoc_mutation_probability(my_mutator_t *data) {
return 5; // 5 %
}
/**
* Determine whether the fuzzer should fuzz the queue entry or not.
*
* (Optional)
*
* @param[in] data pointer returned in afl_custom_init for this fuzz case
* @param filename File name of the test case in the queue entry
* @return Return True(1) if the fuzzer will fuzz the queue entry, and
* False(0) otherwise.
*/
uint8_t afl_custom_queue_get(my_mutator_t *data, const uint8_t *filename) {
return 1;
}
/**
* Allow for additional analysis (e.g. calling a different tool that does a
* different kind of coverage and saves this for the custom mutator).
*
* (Optional)
*
* @param data pointer returned in afl_custom_init for this fuzz case
* @param filename_new_queue File name of the new queue entry
* @param filename_orig_queue File name of the original queue entry
* @return if the file contents was modified return 1 (True), 0 (False)
* otherwise
*/
uint8_t afl_custom_queue_new_entry(my_mutator_t *data,
const uint8_t *filename_new_queue,
const uint8_t *filename_orig_queue) {
/* Additional analysis on the original or new test case */
return 0;
}
/**
* Deinitialize everything
*
* @param data The data ptr from afl_custom_init
*/
void afl_custom_deinit(my_mutator_t *data) {
free(data->post_process_buf);
free(data->mutated_out);
free(data->trim_buf);
free(data);
}
afl_custom_post_process 를 이용해 반드시 모든 인풋이 FUZZ_로 시작하게하고
afl_custom_fuzz 에서 미리정해둔 commands의 "AAA", "BBB", "CCC" 중 하나를 골라 뒤에 이어붙인 뒤 퍼저가 생성한 인풋과 이어붙이는 방식이다.
이를 이용해 퍼징을 진행하면 아래와 같이 인풋들이 전달된다.

중간중간 FUZZ_* 등 AAA BBB CCC 가 붙지 않는 경우가 있는데 그동안은 내가 만든 것이 아닌, 다른 뮤테이션 전략이 선택되었기 때문이다.
이처럼 FUZZ_가 항상 붙은 인풋이 전달되는 것을 확인할 수 있고
1-3 방법론과 다른 것은 crash가 발생했을때도 실제로 input으로 들어간 것과 동일한 형태의 값을 Fuzzer가 인지하고 있다는 것이다.
따라서 1-4 방법이 좀 더 정석적이다.
왜냐하면 생성한 mutation 값을 바꿔주고 이를 퍼저에게 전달한다고 기억할 수 있도록 인지시켜주는 개념이고
1-3은 단순히 퍼저가 생성한 mutation 값을 전달하기 직전에 퍼저가 모른채로 전달하는 방법이다.