설명 가능한 정기예금 가입 여부 예측을 위한 앙상블 학습 기반 분류 모델들의 비교 분석
정기예금 가입 여부 예측은 은행의 대표적인 금융 마케팅 중 하나로, 은행은 다양한 고객 정보를 활용하여 예측 모델을 구성할 수 있다. 정기예금 가입 여부의 분류 정확도를 향상하기 위해, 많
www.kci.go.kr

본 논문은 정기예금 가입 여부를 예측하기 위해 머신러닝을 사용하고 이때 가장 적합한 머신러닝 모델을 찾아가는 내용이다.
특히 핵심적인 내용은 정기예금 가입 여부 예측을 위해 분류모델 (가입한다 / 안한다)을 이용하고 이때 설명가능한 AI (XAI)를 도입하여 기계학습된 분류모델들의 의사결정 과정에 대한 근거를 적절하기 설명할 수 있도록 유도한다.
랜덤 포레스트, GBM, XGBoost, LightGBM과 같은 의사결정 트리 기반 앙상블 학습기법들을 이용하여 분류 모델들을 개발했고 교차검증을통해 모델들의 분류성능을 분석했다.
서론
은행의 입장에서본 정기예금의 장점과 정기예금 가입 여부 예측의 필요성
정기예금 : 고객(예금자)이 금융기관과 사전에 일정 기간을 정하여 원금과 이자를 수취하기 위한 목적을 갖는 금융상품
=> 은행은 정기예금을 이용해 투자 또는 대출 위한 자본금으로 운용할 수 있어 높은 경제적 이득을 기대할 수 있다.
=> 이에 많은 고객들이 정기예금을 가입할 수 있도록 금융 마케팅을 열심히 하고있다.
=> 기존 고객 데이터들을 이용해 잠재적인 고객을 파악할 수 있다면 (이사람이 가입할지말지 예측) 참 좋다.
'정기예금 가입 여부' 데이터 특성
여기서 정기예금 가입 여부는 범주예측 또는 분류(Classification)에 속하는 지도학습(Supervised Learning)의 일종이며 나이, 직업, 자산 등 다양한 고객 정보를 고려하여 인공지능 (Artificial Intelligence, AI) 기반의 분류 기법들 이 보고되고 있다.
고객 정보 (나이 / 직업 / 자산)들을 이용해 => 정기예금 가입 여부를 예측함.
이때 정기예금 가입 여부는 분류 기반의 지도학습을 이용함 (가입한다 / 안한다)
기존 연구의 한계
이전 연구에서 사용한 우수한 분류모델 : 인공 신경망(Artificial Neural Network, ANN) 기반의 분류 모델
=> 우수한 성능(우수한 분류 정확도)을 가지고있지만 블랙박스와 같이 독립변수들의 영향도와 모델의 의사결정 과정을 파악하기 어렵다.
=> 인공지능 기반의 분류 또는 예측 모델이 항상 정답만 도출하는 것은 아니므로, 부정확 한 예측을 수행할 때 그 이유를 파악할 수 있는 근거가 필요하다. 하지만, 대다수의 인공지능 모델은 그 근거를 확인하기가 쉽지 않아 모델 의 신뢰성을 확보하는 데 한계를 보이며, 이 로 인해 실제 산업에서 적용하기가 어려울 수 있다.
본 연구의 정체성 및 세팅
본 연구의 정체성 (기존 연구의 한계 극복)
앞서 기술한 문제를 해결하기 위해, 설명 가능한 인공지능(Explainable AI, XAI)에 대한 중요성이 증대되고 있으며, 본 연구에서도 SHAP (SHapley Additive exPlanations)을 각 모델에 적용하여 개인의 신용 등급을 평가하는데 어떤 독립변수가 중요한지를 분석한다. 예전에 사용한 연구들을 간단히 살펴보면
(예시 - 신한은행)
사용한 데이터 셋 : HELOC(Home Equity Line of Credit), Lending Club, UCI의 Default of Credit Card Clients 데이터 셋
이용한 모델 : GBM(Gradient Boosting Machine), XGBoost(eXtreme Gradient Boosting)를 이용하여 모델을 구성하였으며
적용한 XAI기법 : SHAP (SHapley Additive exPlanations)을 각 모델에 적용하여 개인의 신용 등급을 평가하는데 어떤 독립변수가 중요한지를 분석함
연구 세팅
목표 : 본 논문은 AI 모델의 신뢰성을 확보하기 위해, 정기예금 가입 여부 예측에서 고객 정보의 영향도와 의사결정 과정을 해석할 수 있는 설명 가능한 분류 모델을 제안
사용한 데이터 셋 : Bank Marketing Dataset
=> 포르투갈의 은행 데이터 총 11,163개의 튜플
=> 독립변수 : 고객의 개인 인적사항 과 텔레마케팅 정보
=> 종속변수 : 정기예금 가입여부
이용한 모델 : 테이블 형식의 데이터(Tabular Data)에서 우수한 예측 성능을 도출하는 DT 기반의 앙상블 학습 기법들(DT 기반 앙상블 학습 기법인 랜덤 포레스트, GBM, XGBoost, LightGBM (Light Gradient Boosting Machine))
적용한 XAI 기법 : SHAP을 이용하여 정기예금 가입 여부 예측에서 고객 정보의 영향도와 모델의 의사결정 과정을 해석
설명 가능한 정기예금 가입 여부 예측 기법
데이터 전처리
수집한 데이터 셋의 범주형 데이터는 모델 학습을 위해 다음과 같이 처리했다.
문자형(Character) 변수 : 원핫 인코딩(One-Hot Encoding)을 수행하여 해당 속성이 속하면 1, 그렇지 않으면 0
논리(Logical) 또는 부울(Boolean) 변수 : Yes는 1, No는 0
=> 총 48개의 독립 변수를 이용, 종속변수인 Deposit(가입: 1, 미가입: 0)을 예측하기 위한 앙상블 학습 기반 의 분류 모델들을 구성
사용할 알고리즘 선정
앙상블 학습은 여러 단일 모델을 전략적으로 생성하고 결합하여, 단일 모델보다 우수한 분류 및 예측 성능을 도출하는 방법론이다. 대표적인 앙상블 학습 방법론으로 배깅(Bagging), 부스팅 (Boosting), 스태킹(Stacking)이 있다.
<앙상블 학습 방법론>
배깅 : 배깅은 부트스트랩(Bootstrap)과 Aggregating의 합성어로 부트스트랩은 표본 분포를 구하기 위해 데이터를 여러 번 복원 추출 (Resampling)하는 것.
=> 주어진 데이터 셋을 무작위로 복원 추출하여 분할된 각 데이터 셋에서 병렬적으로 DT와 같은 단일 모델을 구성한다. 다음으로, 단일 모델들의 예측값을 집계하여, 분류는 투표(Voting), 회귀는 평균(Average)으로 집계한다. 배깅은 여러 경우의 데이터 셋을 학습하여 최종값을 도출하기 때문에 낮은 분산으로 인해 이상치에 강인하다.
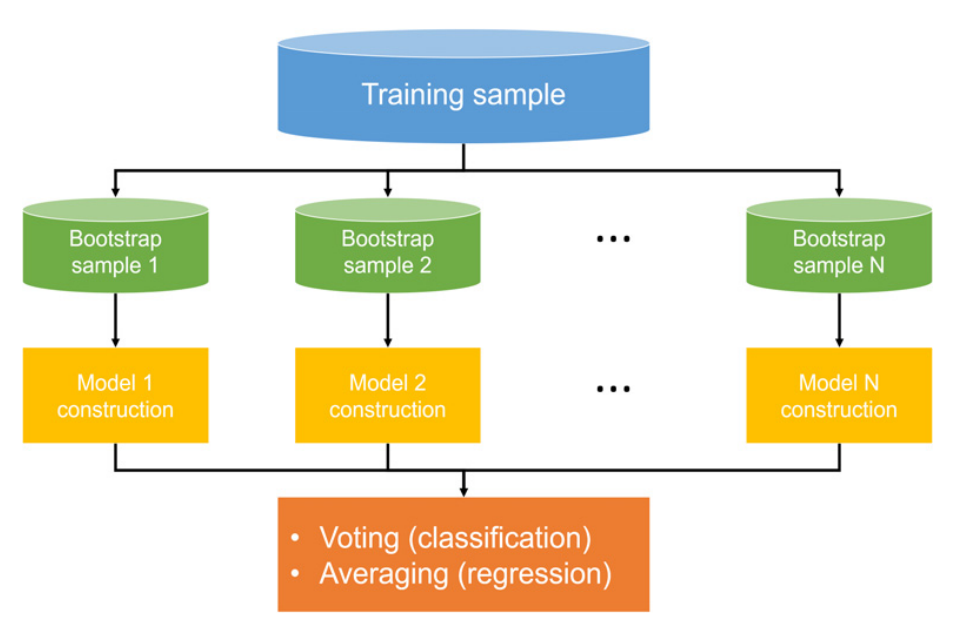
부스팅 : 단일 모델의 잔차를 다음 단일 모델이 학습하여 잔차를 줄이는 학습 방식
=> 부스팅은 최종 예측값을 집계하는 방식은 배깅과 유사하나, 병렬 학습인 배깅과는 다른 학습 방식으로, 단일 모델의 잔차를 다음 단일 모델이 학습하여 잔차를 줄이는 학습 방식이다. 그러니까 이전 모델에서 학습하여 나온 결과들을 이용해서 또 학습을 진행하는 것이다. 정교한 예측 성능을 기대할 수 있지만, 오랜 학습 시간 및 과적합(Overfitting) 문제가 발생할 수 있다.
*부스팅 알고리즘 특징
GBM(Basic Exact Greedy) : DT 모델 을 구성하고, 경사 하강법(Gradient Descent)을 이용
XGBoost : 분산환경에서의 데이터 처리 문제를 효과적으로 다루기 위해 Approximate 알고리즘을 기반으로 데이터 정렬 및 분할을 통해 병렬처리를 수행
=> 학습 속도를 향상. 정규화(Regularization)를 적용해 모델 구조를 간소화하여 과적합 문제를 해결.
LightGBM : GBM, XGBoost보다 더욱 빠른 학습 속도와 정확도 개선을 위해 개발. LightGBM은 GBM과 XGBoost에서 나무를 확장 하는 방식인 Level-Wise 방식이 아닌, Leaf-Wise 방식을 채택하여, Level-Wise에서 동일한 Level로 재조정하는 시간이 소요되지 않아 빠른 학습이 가능함.

스태킹 : 여러 단일 모델을 사용하는 배깅, 부스팅 과는 다른 학습 방식으로 여러 이기종 모델을 구성한 뒤, 각 모델의 예측값을 다시 분류 또는 예측 모델이 학습하여 최종값을 도출하는 방식
=> 본 논문은 분류 모델의 해석을 용이하게 하기 위해 여러 이기종 모델들을 구성해야 하는 스태킹 방법론을 고려하지 않고, SHAP 패키지 에서 제공하는 배깅과 부스팅 방법론만 고려.
=> 이에 총 4가지의 앙상블 학습 기법을 선정
=> 배깅 방법론 : 랜덤 포레스트
=> 부스팅 방법론 : GBM, XGBoost, LightGBM
실험 및 결과
Initial Configuration
컴퓨터 : Intel® CoreTM i5-7600 CPU @ 3.50GHz와 16GB DDR4 RAM
머신러닝 알고리즘 및 XAI 라이브러리 : Python 3.7.9와 PyCharm 2020.3.3의 프로그래밍 개발 도구를 통해 랜덤 포레스트, GBM 및 성능 평가 지표로는 scikit-learn 0.24.2, XGB는 xgboost 1.4.2, LightGBM은 lightgbm 3.2.1의 라이브러리
사용한 데이터 : Kaggle에 서 수집한 1,02MB의 크기를 가진 원본 데이터를 전처리하여 1,13MB의 크기를 가진 데이터 셋
검증 방법
본 논문은 분류 모델의 성능을 심층 분석하기 위해 와 같이 10겹 교차검증 (10-Fold Cross-Validation)[36]을 적용하였다. 10겹 교차검증은 모델의 성능을 분석하기 위해 데이터 셋을 모두 활용하여 검증하므로 모델의 신뢰성을 높일 수 있다는 장점이 있다.
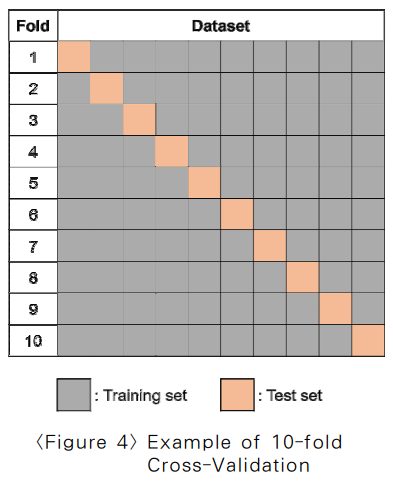
1. 주어진 데이터 셋에서 비복원 추출 방식을 통 해 총 10개의 임의의 데이터 셋을 추출한다.
2. 추출한 임의의 데이터 셋은 1부터 10까지 모든 임의의 데이터 셋에 대해 검증
3. 검증할 임의의 데이터 셋을 제외한 나머지 9개의 임의의 데이터 셋으로 모델을 학습하는 방식으로 총 10번을 반복 검증한다.
실험 결과
테이블 형식의 데이터에서 신경망 모델들(ANN_1, ANN_2, DNN)의 적합성
신경망 모델들은 다양한 분야에서 우수한 성능을 도출하였으나, 해당 데이터 셋에서 는 다소 불만족스러운 성능을 도출하였다.
=> 초매개변수를 기본값으로 설정하여 실험하였기 때문
=> 최적의 신경망 모델을 구성하기 위해서는 많은 시간이 필요함(적절한 초매개변수를 찾는)
*사용한 신경망 모델
ANN_1 : 최적화 알고리즘으로 SGD (Stochastic Gradient Descent), 180개의 노드의 수를 갖는 1층의 은닉층, 학습률 변화를 Constant 방식으로 학습된 모델이다.
ANN_2 : 학습률 변화만 Adaptive 방식이며, 나머지 모델 구조 는 ANN_1과 같다.
DNN : 각 64, 128, 64개의 노드의 수를 갖는 3층의 은닉층으로 구성된 심층 신경망 모델이다.
또한, 신경망 모델은 DT 기반의 앙상블 학습 모델보다 설명하기가 어렵다는 단점이 있음
=> DT 기반의 앙상블 학습 모델이 Bank Marketing Dataset과 같은 테이블 형식의 데이터에서 더욱 적절하다는 것을 확인할 수 있었다.
최종 결과
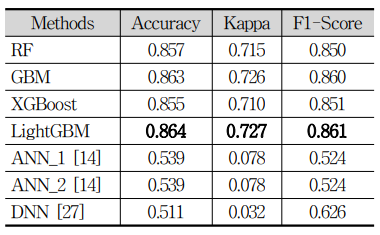
1. 평가 지표로 정확도, 카파 상관계수, F1-Score를 적용한 결과 실험 결과, LightGBM이 0.864의 정확도, 0.727의 카파 상관계수, 0.861의 F1-Score로 가장 우수한 성능을 도출하였다.
2. Duration을 제외하였을 때 에는 GBM이 0.738의 정확도, 0.469의 카파 상관 계수, 0.693의 F1-Score로 가장 우수한 성능을 도출하였음을 확인할 수 있었다.
(SHAP 결과)
3. 모든 독립변수 중 상위 7개인 Duration, Age(나이), Housing(주택담보대출)과 같은 특정변수들의 영향도를 분석하였다.
=> 통화시간이 500초보다 짧을 때
=> 주택담보대출 또는 개인 대출을 보유하고 있을 때
=> 30대부터 50 대까지의 고객
=> 정기예금 가입에 긍정적인 반응을 보인다는 것을 확인
특정 고객의 정보를 SHAP 기법에 적용하여 분류 모델의 의사결정을 확인 할 수 있었다.
=> 전반적으로 Duration(통화시간 => Unseen 데이터. 정기예금 가입을 할 잠재 고객을 찾는 목적으로 확인하기 어려운 데이터)을 제외한 데이터 셋이 여러 독립변수를 효과적으로 고 려하여 예측값을 도출한다는 것을 확인할 수 있었다.
연구의 한계점
포르투칼의 데이터를 사용함.
추후 => 국내 실제 금융 데이터를 확보 => 모델 성능 고도화 및 해석 => 국내 금융 산업에서 실질적인 도움 가능
'공부 > 논문 리뷰' 카테고리의 다른 글
| Xu et al. Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection. (CCS 2017) 요약 (2) | 2024.03.05 |
|---|---|
| 머신러닝 기반 비트코인 네트워크 불법거래 계정/트랜잭션 탐지 시스템 리뷰 (1) | 2022.07.10 |